前言
在使用大模型进行推理时我们都会觉得模型的推理速度比较慢,当前也有很多推理加速的方法,像是模型量化、FlashAttention、使用更好的GPU、KVCache等,今天我们就来聊聊KVCache是怎么回事,我会从transformer decoder的推理过程开始,到为什么KVCache可以加速模型推理,以及具体的效果进行介绍。
Transformer的self-attention机制
目前的大模型都是基于Transformer的decoder架构进行设计的,所以先把著名的self-attention公式抛出来。
由于大模型使用的是decoder,所以在计算时会mask掉当前token的后边的token,例如当前为token_n,mask矩阵会mask掉n之后的所有token值,目的是防止解码过程中看到答案。
下图是GPT2的解码过程,给定输入,模型预测下一个token,然后在下一步中使用上一步预测的token作为输入再次进行预测。图来源:https://jalammar.github.io/illustrated-gpt2/
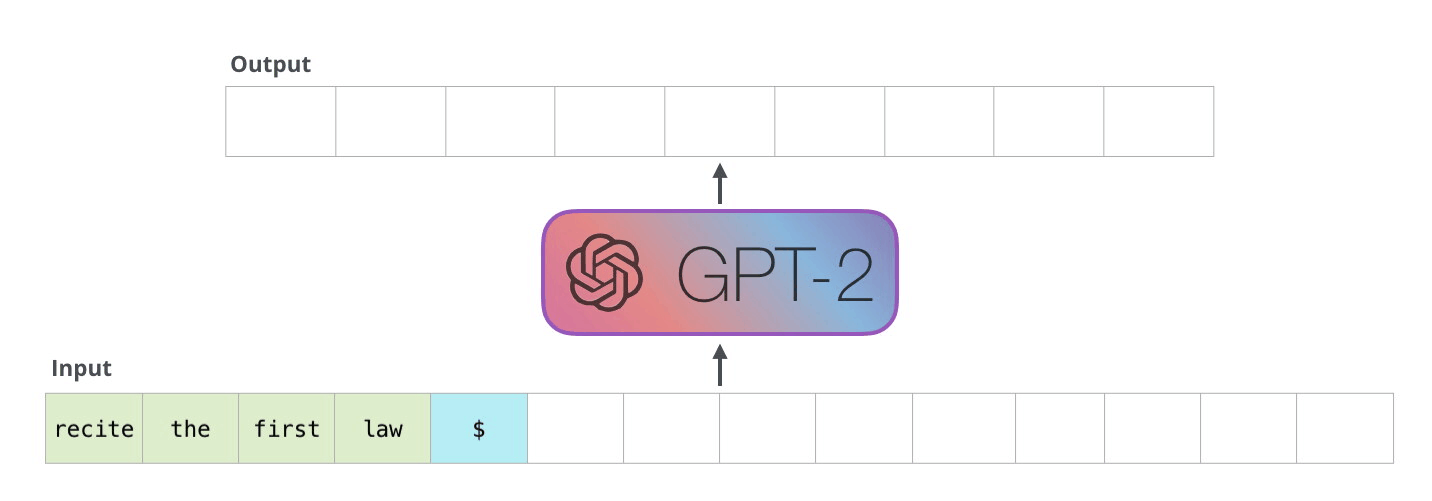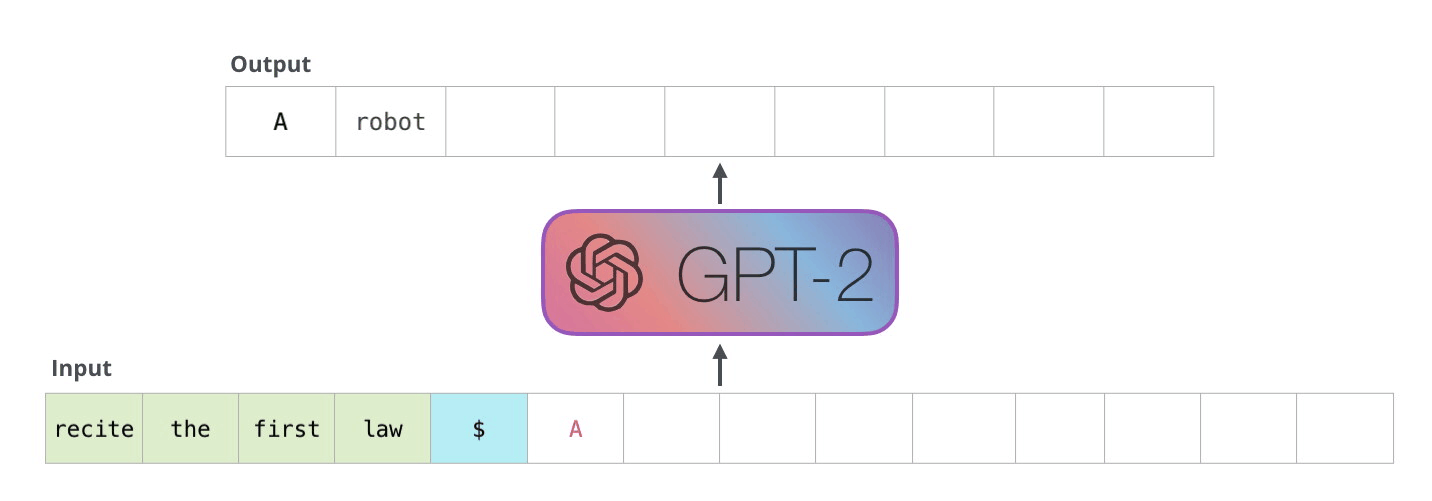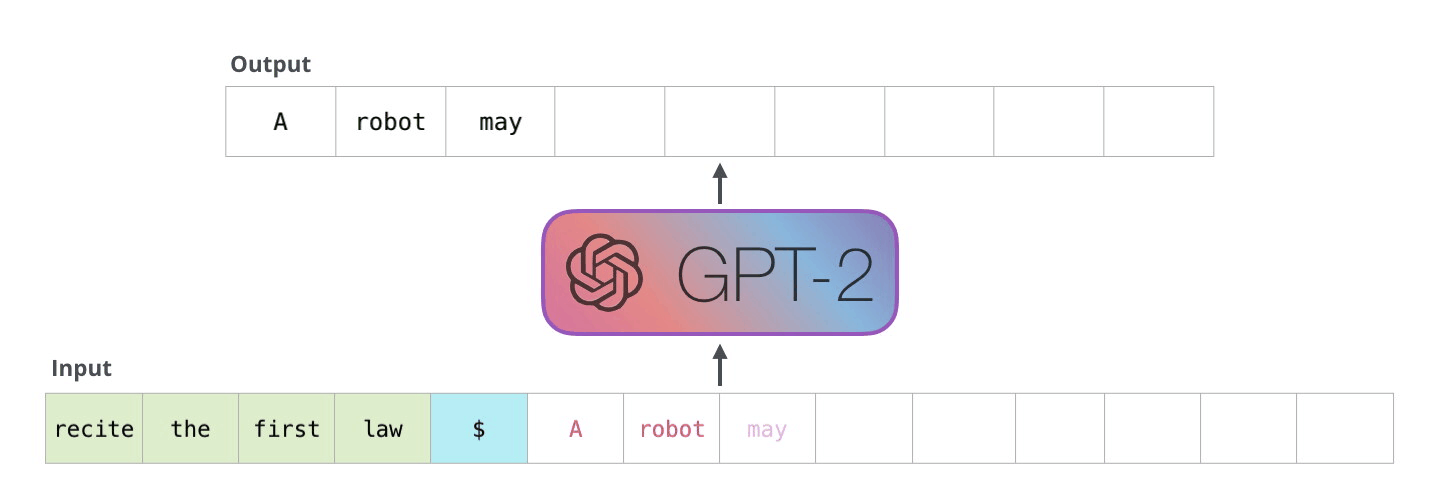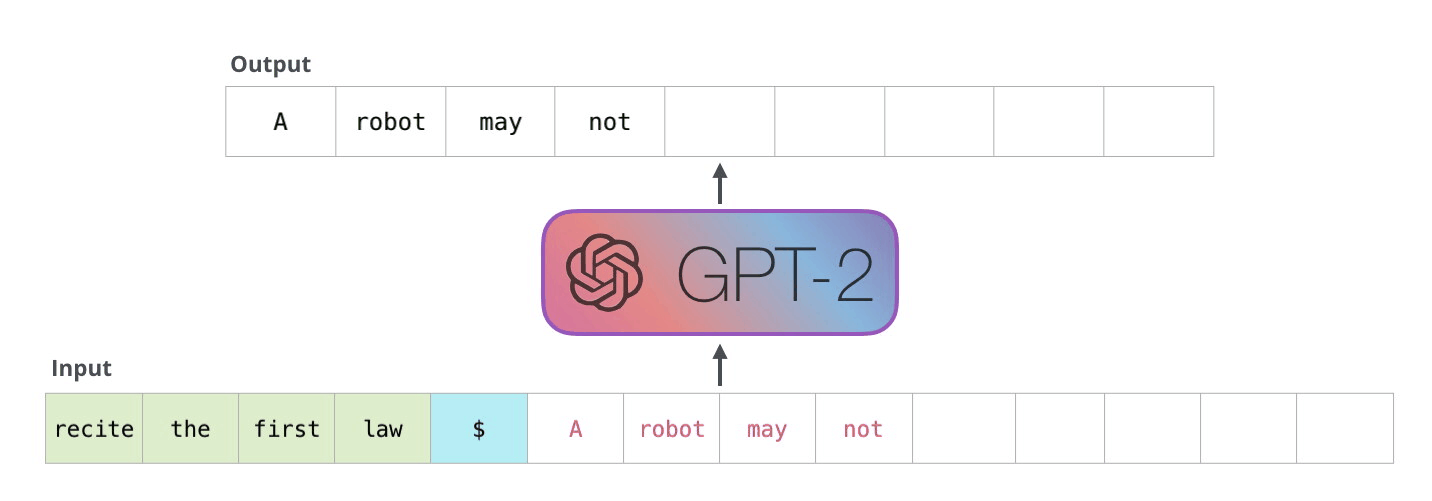
我们来逐步计算一下解码的过程。
因为decoder中的self-attention是masked self-attention,所以在计算时需要注意进行mask。
我们将q和k的计算整理成矩阵,可以得到以下公式。
展开的话就是这样的一个矩阵。
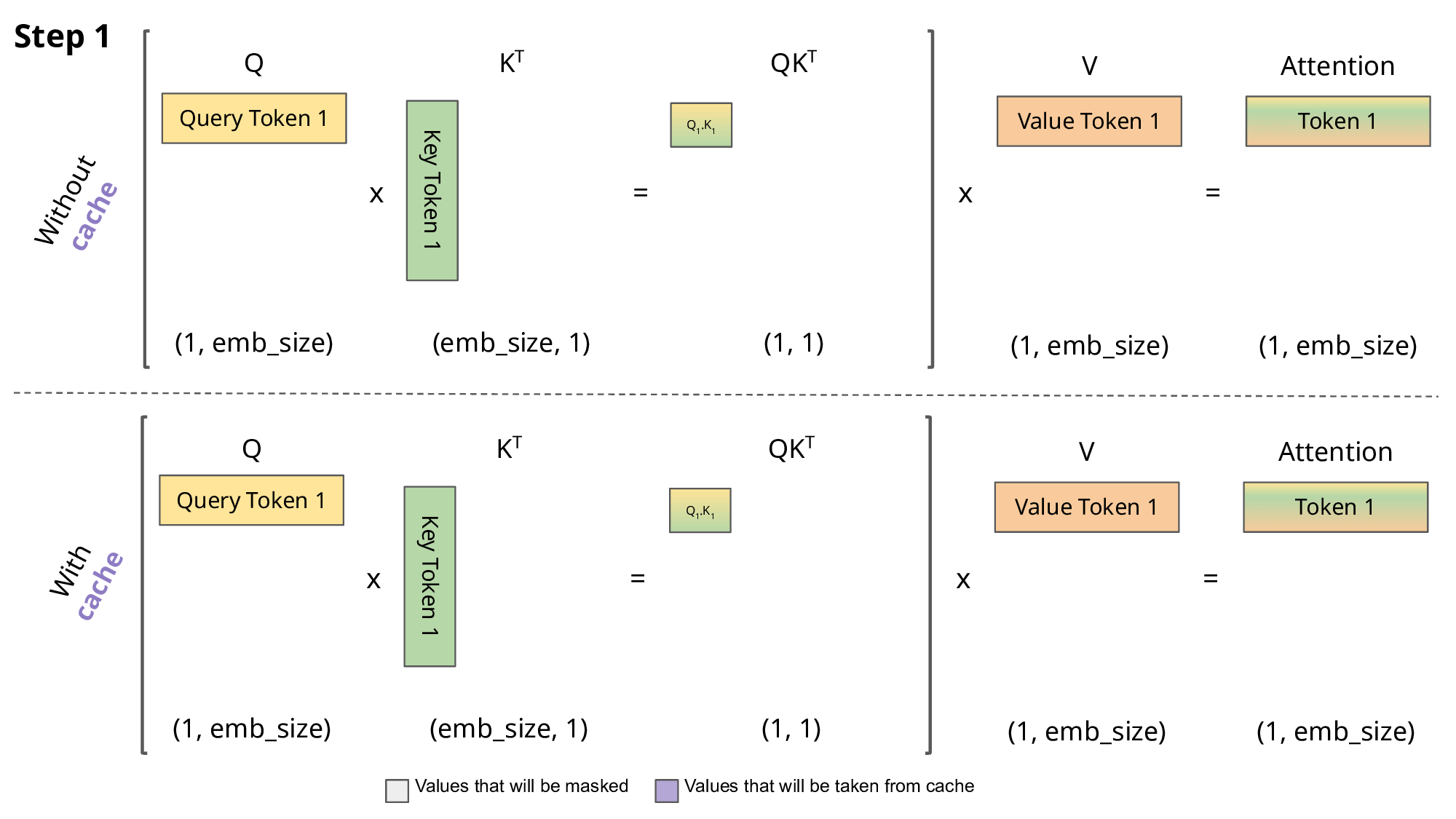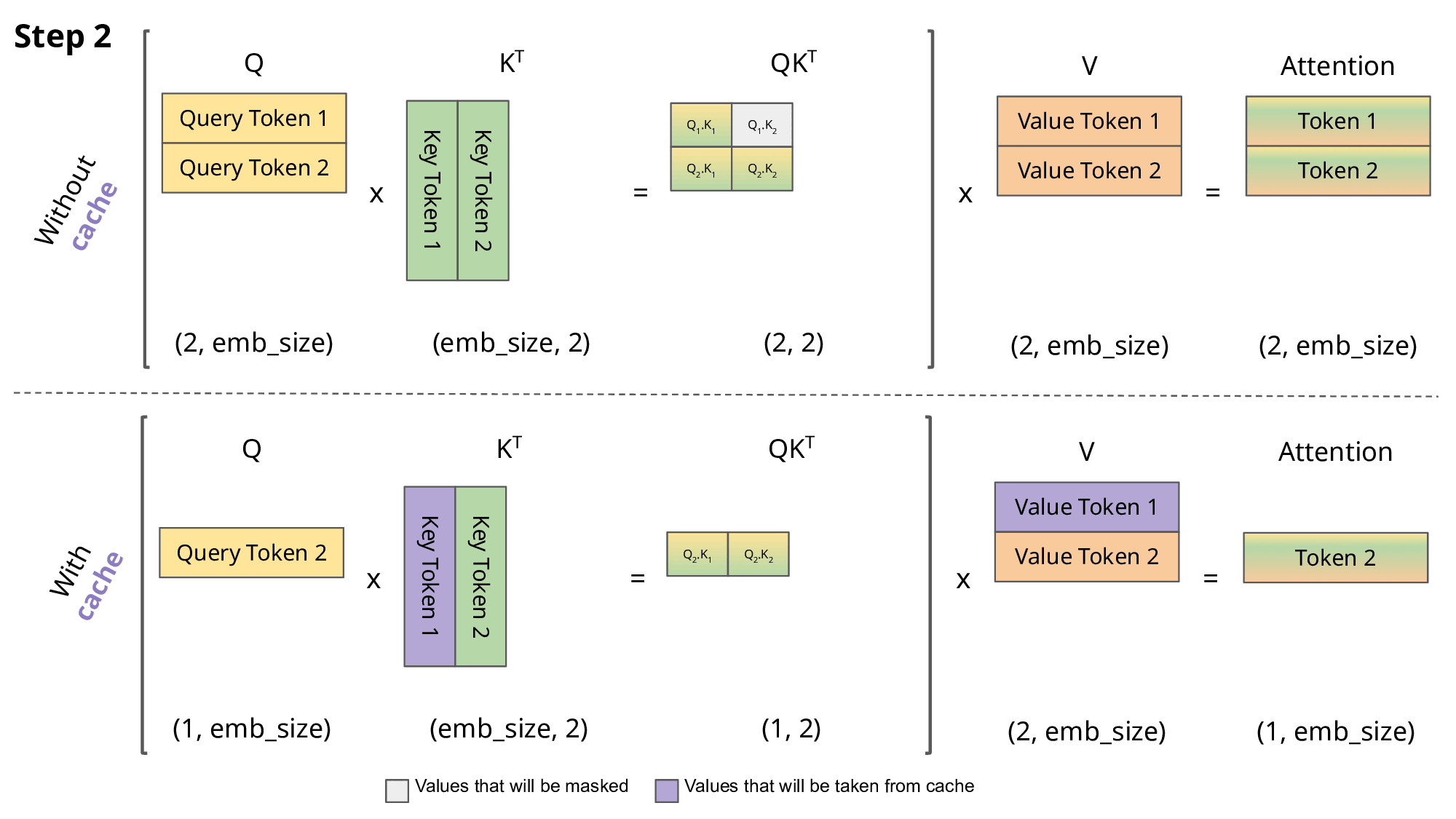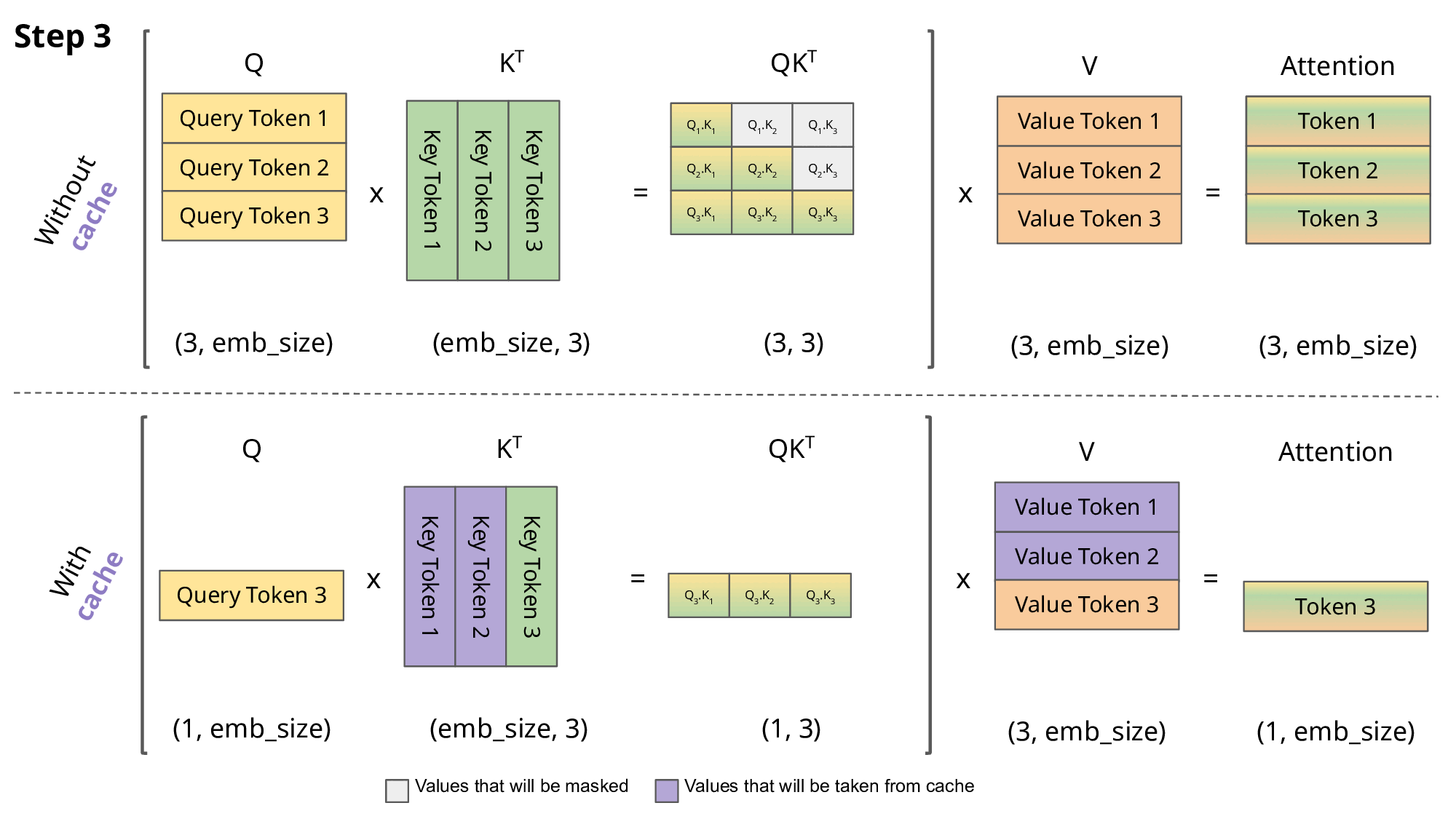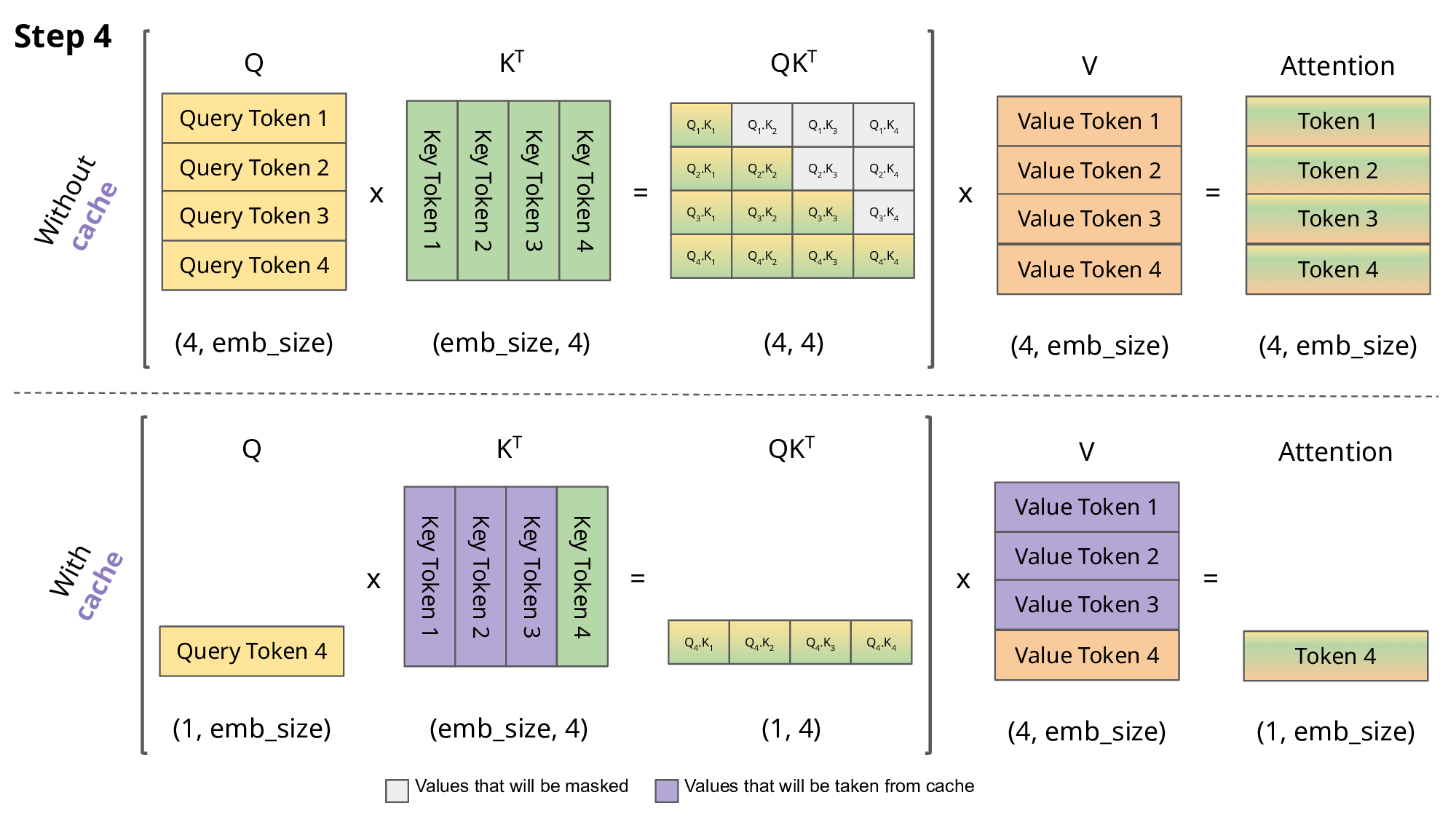
对于token_1,Attention_1(Q,K,V)=softmax(\frac{Q_1K^T_1}{\sqrt{d_k}})\vec{V_1}
对于token_2,Attention_2(Q,K,V)=softmax(\frac{Q_2K^T_1}{\sqrt{d_k}})\vec{V_1}+softmax(\frac{Q_2K^T_2}{\sqrt{d_k}})\vec{V_2}
对于token_3,Attention_3(Q,K,V)=softmax(\frac{Q_3K^T_1}{\sqrt{d_k}})\vec{V_1}+softmax(\frac{Q_3K^T_2}{\sqrt{d_k}})\vec{V_2}+softmax(\frac{Q_3K^T_3}{\sqrt{d_k}})\vec{V_3}
可以看到在token_2推理的过程中,K_1、V_1是重复使用的;可以看到在token_3推理的过程中,K_1、V_1、K_2、V_2是重复使用的。
还可以看出来,每次计算attention只需要使用当前的Q即可,并不需要之前的向量。
所以我们就可以把之前计算过的K、V缓存起来,这就是今天我们要介绍的KVCache。
KVCache的作用
现在我们就可以给KVCache进行定义了,在decoder-only架构中,通过缓存解码过程中的K、V,来避免重复计算,从而达到推理加速的效果。
下图清晰了对比了使用KVCache和不使用KVCache的区别,图来源https://medium.com/@joaolages/kv-caching-explained-276520203249
实现细节
在huggingface的transformers中,通过modelling_gpt2.py可以看到具体的实现细节。
query = self._split_heads(query, self.num_heads, self.head_dim)
key = self._split_heads(key, self.num_heads, self.head_dim)
value = self._split_heads(value, self.num_heads, self.head_dim)
# 通过layer_past来传递上一次计算的key value
if layer_past is not None:
past_key, past_value = layer_past
# 通过拼接来得到最新的key 和 value
key = torch.cat((past_key, key), dim=-2)
value = torch.cat((past_value, value), dim=-2)
if use_cache is True:
present = (key, value)
else:
present = None
在transformers中使用KVCache对比
在Transformers中进行对比开启KVCache后的效果。
import numpy as np
import time
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained("gpt2")
model = AutoModelForCausalLM.from_pretrained("gpt2").to(device)
for use_cache in (True, False):
times = []
for _ in range(10): # measuring 10 generations
start = time.time()
model.generate(**tokenizer("What is KV caching?", return_tensors="pt").to(device), use_cache=use_cache, max_new_tokens=1000)
times.append(time.time() - start)
print(f"{'with' if use_cache else 'without'} KV caching: {round(np.mean(times), 3)} +- {round(np.std(times), 3)} seconds")
因为我是跑在M1上,所以对比比较明显,开启KVCache后比不开启能快100倍。
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
with KV caching: 32.101 +- 0.737 seconds
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
without KV caching: 3516.684 +- 27.119 seconds
MHA MQA GQA
目前很多模型,像是LLaMA、Qwen,都使用GQA,其目的也是为了提高模型运行的速度,我们也可以从KVCache的角度去理解这些方法,他们的目的其实就是为了减少KV的个数,从而减少KVCache。
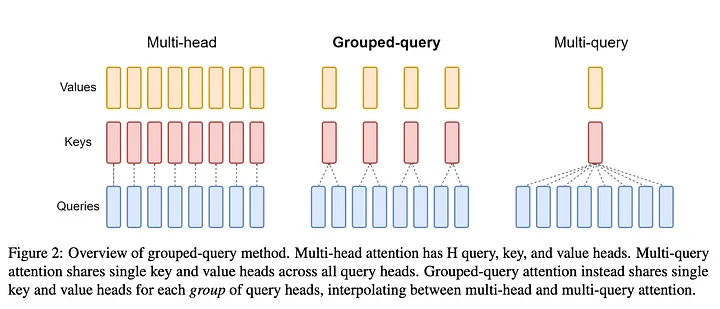
MHA(Multi-Head Attention),传统的Transformer的attention机制,也就是对query、key、value分别使用单独的头,每个头独立处理输入的不同方面,优点就是独立计算,效果最好,但是计算成本太高。
MQA(Multi-Query Attention),所有的query、key、value使用一个头,这样就大大降低了计算成本,比MHA快的多,但是会影响模型的效果。
GQA(Grouped-Query Attention),是MHA和MQA的中间地带。将多个头进行分组,每个组内共享一个key和value,这样每个组的头数较少,所以比MHA快,并且头数不是一个头,所以效果要比MQA要好。
显存分析
假设输入的序列长度是 𝑚,输出序列长度是 𝑛 , 𝑏 为数据批次大小, 𝑙 为层数, ℎ 为隐向量维度,以 FP16(2bytes) 来保存,那么 KVCache的峰值显存占用大小为 𝑏(𝑚+𝑛)ℎ∗𝑙∗2∗2=4𝑏𝑙ℎ(𝑚+𝑛) ,第一个 2 代表 K、V,第二个 2 代表 2bytes。可见随着批次大小和长度的增加,KVCache 的显存占用也会快速增大。
所以KVCache的显存占用跟序列长度是正相关的,现在模型动不动就是4k上下文,甚至上百万上下文,这对GPU的显存占用是很大的,具体解决的方法有以下三个。
- 分配一个最大容量的缓冲区,要求提前预知最大的token数量。如果用户的上下文很短的花,这样会很浪费资源。
- 动态分配缓冲区,先设置固定的容量,超过了就进行扩容处理,但是在在GPU上频繁申请、释放内存的开销是很大的,效率不够高。
- 不数据拆散,按最小单元存储,使用一个元数据记录每一个数据的位置。这就是大名鼎鼎的PagedAttention,也就是vLLM的主要技术。
单向注意力VS双向注意力
最后我们来聊聊为什么LLM都是使用decoder-only的架构,也就是单向注意力机制。
在GPT3之前,BERT在NLP领域是绝对的霸主,几乎所有的任务都会使用BERT去做,都能达到SOTA的水平,BERT使用的是Transformer的encoder架构,也就是双向注意力机制。在GPT3之后,我们见识到了大力出奇迹,尤其是ChatGPT爆火以后,我们见识到了decoder-only的架构,也就是单向注意力的威力。那为什么单向注意力加上超大规模的预训练后效果这么好呢?
苏剑林老师的博客中做了简单的实验,证明了“输入部分的注意力改为双向不会带来收益,Encoder-Decoder架构的优势很可能只是源于参数翻倍。”也就是在同等参数量、同等推理成本下,decoder-only的架构是最优选择。
还有就是大家都在讨论的低秩问题。在输入部分使用双向注意力机制,输出部分使用单向注意力机制,也就是Prefix LM的做法,直觉上是最优的选择,但是双向注意力机制的低秩问题会带来效果下降。具体的细节大家可以参考苏剑林老师的博客,我就不重复了,实在没有苏剑林老师写的专业。
顺着这个问题,在知乎上看到了一篇论文,《What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization?》,这篇论文在50亿参数和1700亿tokens上的预训练任务做了对比实验,得出了以下结论。
- 如果大模型制作无监督预训练,那么decoder-only架构+NTP(next token prediction)任务的zero-shot泛化能力最佳。
- 无监督预训练+multitask finetuning后,encoder-decoder架构+MLM(masked language modeling)任务的zero-shot泛化能力最佳。 所以,在只使用无监督预训练任务的前提下,让模型可以处理开放性问题单向注意力机制是最优的选择。而想要在特定的任务下得到最优可以选择encoder-decoder架构或者encoder架构,使用无监督预训练+finetuning。
题外话
这里简单提一下decoder-only架构的模型是如何处理prompt的,前边我们提到这种架构的模型在输出的时候是通过上一步生成的结果来推理下一个token,那我们输入的prompt是一整句话,模型怎么编码呢?理论上来说也需要通过上一个token预测下一个token,但是因为我们输入的句子是确定的,也就是我们已经知道的prompt的上下文了,所以没必要通过上一个token来预测下一个token了,并且我还需要对其进行编码,那就需要mask矩阵来帮忙了。
通过上边self-attention的矩阵可以看到,我们可以实现一个下三角的矩阵,来实现当前token看不到后边token的效果。所以在处理prompt时,我们会编码整个句子,然后通过乘上这样的下三角矩阵来实现一个token一个token编码的效果。
这就实现了prompt并行处理的效果,从openAI的api定价上也能看出来,input的价格是比output的价格要低的,就是因为input可以并行处理,比较节省算力。

总结
本文算是我的学习笔记,从什么是KVCache,到实现方法及其效果,延伸到单向注意力机制的问题,参考了大量的博客。目的是让自己弄清楚怎么回事,如果能帮助到读者那将是我的荣幸,如果我写的不够清楚,欢迎大家阅读参考文献的原文。
参考文献
Transformers KV Caching Explained
LLM Inference Series: 3. KV caching explained
LLM Inference Series: 4. KV caching, a deeper look
为什么现在的LLM都是Decoder only的架构? - CastellanZhang的回答 - 知乎 https://www.zhihu.com/question/588325646/answer/3002928687