动机
微信公众号几乎是中文信息领域质量最高的平台,有很多文章值得细读,那就需要花整块时间进行阅读,并且有的文章在读完后还想收藏起来作为自己的知识库。
我之前使用过微信浮窗、Omnivore作为read later(稍后读),但是存在几个问题,一是微信浮窗有上限,大概是100篇,如果超过了就不能再加了,虽然稍后读是尽快读完,像仓鼠一样存着文章不读也是一种浪费,但是有这种限制总会让人不爽。二是读完以后没有地方进行保存,即使收藏到微信上,也有可能因为作者把文章删除了,或者某些不可抗性被删除了,就会导致永久丢失。Omnivore可以将文章保存下来,但是Omnivore前段时间刚刚被收购,不提供服务了,虽然开源了源代码,但是自部署也是挺麻烦的一件事,并且他提供的文章保存功能面对微信图片、代码之类的内容总会有一些问题,有可能会丢失一部分数据。
于是我打算自己写一个小工具来满足我的需求。需求很简单,统一爬取文章按照原有格式进行保存下来,并且支持打标签保存,如果能够加上一些AI的功能那就更好了。
实现
稍后读功能的使用场景大多数发生在移动端,因为在有电脑的场景下,大概率是有时间和场所进行深度阅读的,所以我想到了使用苹果的「快捷指令」来进行实现,可以读取粘贴板上的文章网址进行保存,并且可以使用iPhone的Action Button快速触发,任务在后台执行,执行完成发送执行结果通知即可。
具体保存的位置我选择的是Notion,Notion基本是我的第二大脑,我所有的文本相关的数据都存储在Notion中,支持全局搜索和Notion AI,并且Notion API也很好用,支持数据上传和修改,非常方便。
前段时间黑五,我以很便宜的价格购买了VPS,本来想用来部署博客的,现在正好使用这台机器来部署我的服务。
第一版本
通过快捷指令中的url访问功能,实现了对文章链接的访问,基于规则识别了文章标题和作者,将其与url一起通过Notion API保存到了我的Notion数据库中。
这一版只解决了部分数据保存的问题,并没有实现本地化阅读的功能。因为通过快捷指令只能实现文本的内容,文本格式、图片、链接等都无法获取,更不用说按照原有样式保存下来了。
我使用了两天,基本是在手机上保存链接,在电脑的Notion客户端进行阅读。因为没有本地保存,所以基本看完就删除了,体验并不比之前好多少。
第二版本
使用Python正式实现了API,通过快捷指令向VPS发送请求,然后在VPS进行爬取文章内容,保存到Notion中。这一步看起来很简单,不就是一个爬虫嘛,实现起来确实花费时间最长的地方。
我开始认为微信文章不都应该是统一格式的吗,于是决定自己写爬虫去爬取文章内容,只要将内容的HTML标签同步保存下来,再转换成Markdown不就可以了。在实际实现的过程中我才发现文章的HTML会因为文章的排版不同而变化,基础的内容爬取很简单,想要复现文章原本的样式,几乎是不可能的,需要处理太多种情况了。
我转而想到了开源的方法,去github一通搜索,也没有找到很好的方法。因为工作内容是NLP和LLM,正好看到Jina AI发布了一个小模型,reader-lm-0.5b,可以将html页面转换成Markdown格式,于是我自己部署了一下,发现效果还可以,但是对于我的场景可能不太适用。
这个模型需要自部署,这对于VPS来说有点不现实,因为本身VPS的配置就不高,即使是0.5b参数的模型部署起来也很困难,再加上一篇文章的HTML长度为一两万很正常,会很影响生成速度。
LLM进行输出内容与爬虫爬取的内容相比,出错的概率肯定是有的,因为LLM是基于上文进行预测下文的,而我的场景是将文章保存下来,不允许有任何文字的错误,所以这一点基本就把这个方法舍弃了。
后来我发现Jina AI支持API调用,这个API调用的并不是reader-lm这个模型,而是先提取HTML内容,然后通过正则等其他的方法,将清理后的HTML转换为Markdown,这正好符合我的要求,在保证了内容不出错丢失的前提下,还能以Markdown的形式保存。还有最重要的一点,免费!当然即使是付费,我也愿意支持付费使用。
我也尝试过微软开源的一个库,markitdown,支持将各种各样的文件转成Markdown格式,我尝试将HTML保存成文件,然后基于这个库进行转换,但是效果不如Jina AI的API效果好。
还有一个比较麻烦的点,那就是图片,因为微信图片是有版权保护的,通过图片的url上传到Notion会报错,所以只能上传到服务器,或者图片托管平台来获取新的图片地址。
因为我的VPS本身存储空间不大,并且如果图片全部上传到这里,未来再做服务器迁移的时候,图片的url也会变化,所以VPS并不合适。还可以选择收费阿里云OSS或者AWS的S3云存储,但是我看基本都是500GB起购买,这对于只存储图片的需求来说,太奢侈了。还有其他的方法,像是telegram免费存储,但是可能会因为网络问题导致不稳定,后来我找到了imgur这个平台,这是一个图片分享和托管平台,可以基于imgur的api实现免费的存储,但是存储的图片如果超过6个月不访问会过期,我只需要手动访问或者写一个程序定时访问即可。
imgurl图片上传有一些限制,那就是图片不能超过特定的尺寸或者大小(10MB),所以我将图片下载下来,检查尺寸和大小,如果超过了,就重新resize一下或者调整一下清晰度,即可上传成功。上传速度还是挺快的,不过有速率的限制,经过测试,如果是一篇图片比较多的文章,将图片全部上传也不会触发速率限制,只要不频繁上传多篇文章即可。
文本内容和格式准备好以后就好说了,我把这个流程梳理成pipeline,使用ChatGPT和github copilot实现了一下,读取url,获取内容,获取作者和发布时间,在Notion数据库中创建页面并保存内容。基本达到了我的要求,我还在Notion数据库中添加了标签的字段,方便我阅读完后进行打标签梳理。
最终版本
还记得我之前提到过,如果加上一些AI功能就更好了嘛,作为LLM工程师,这块实现起来还是挺简单的。对于长文,如果有提纲/总结能够帮助我更快的了解文章的整体结构和结论,也可以帮助挑选我关注的部分,节省我的时间。
目前市面上的开源模型和闭源模型做的都不错,那就选择最便宜的!我选择了qwen2-7b,写好Prompt后,经过测试基本能够满足我的需求。
使用LLM有一个问题那就是运行时间的问题,作为小工具,运行时间长我是可以接受等待的,但是快捷指令对于API的限制是60s,如果超过的话那就会中断,基于此,我将接口改成了异步的形式,先通过请求获取文章内容,在Notion中创建页面,这时候会提示我数据创建成功,然后服务会在后台执行数据写入、AI总结等流程。
下面来看一下效果。
知识库页面,这里我加了一个标语来提醒自己阅读的注意事项。
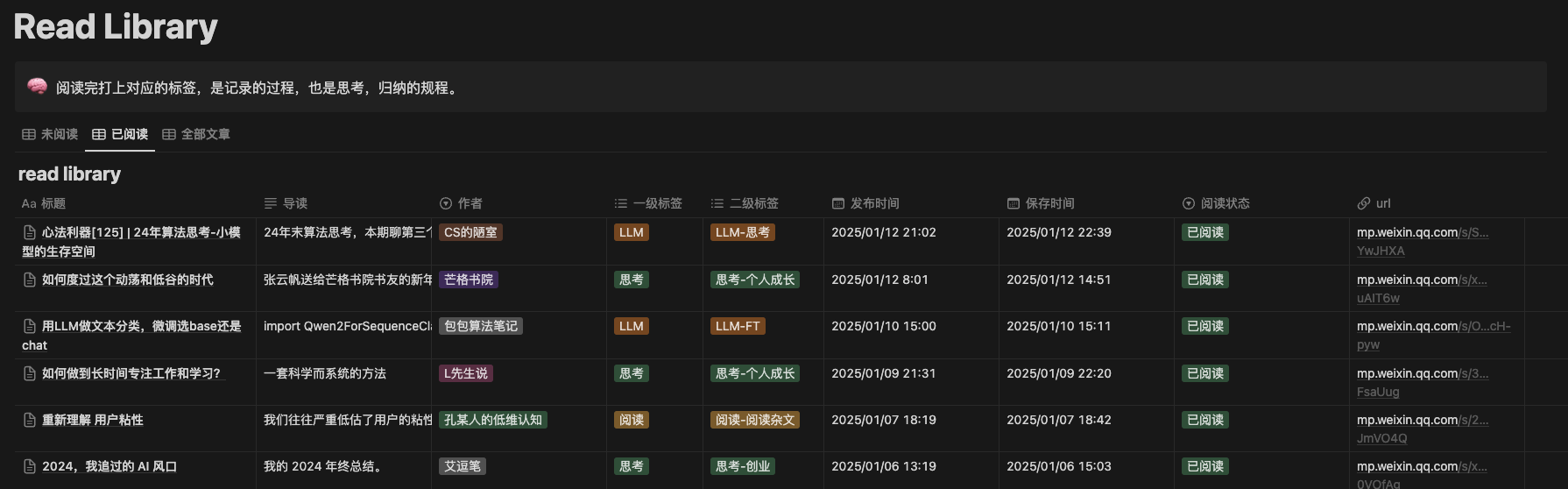
AI总结部分
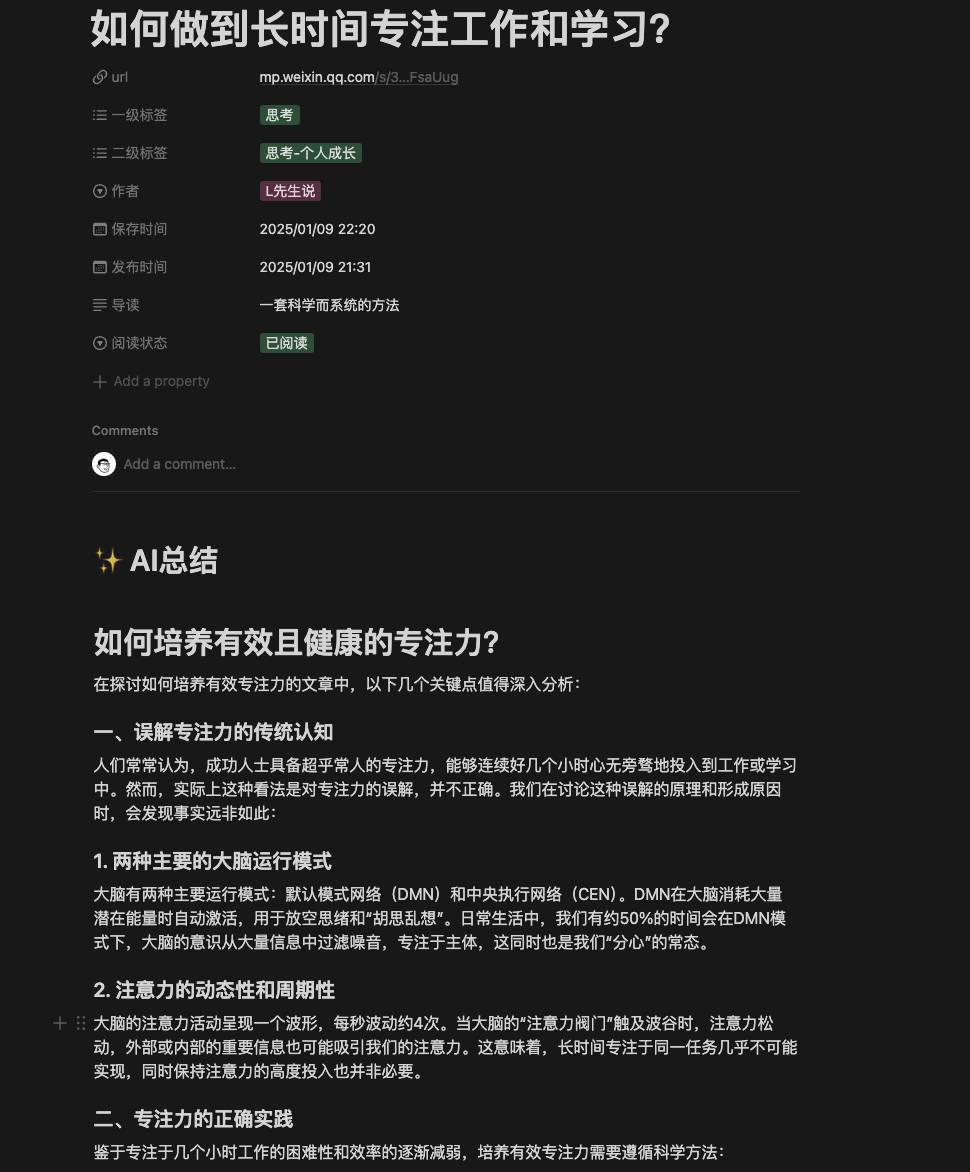
正文部分

总结
为自己制作趁手的小工具不仅方便自己使用,更能带来一种成就感,这是之前只有作为程序员才能享受到的快乐,现在这个时代,其实非程序员借助AI的能力也能实现这些功能。所以如果你遇到一些问题,或者有一些很好的想法,可以马上借助AI行动起来,谁知道后边会开什么花,接什么果呢。
另外我也考虑过将代码开源,但是如果有小伙伴想用的话,前提就是需要自己购买服务器,这可能拦住了大部分人,所以我想以后有机会的话,做一个服务出来,通过我购买的服务器,让想使用这个服务的小伙伴通过配置的方法,实现零代码和零服务器使用服务。